Introduction
I discussed in a previous post of the benefits of DataOps (and showcased MLflow and Kubeflow) and even earlier about the benefits of monitoring distributed systems and Kubernetes, as well as introduced the data-mill project to ease the setup up of data science environments on K8s and enforce dataops principles. Much has changed since then. ML has de-facto become a commodity in most data projects and companies, and several frameworks arose to manage the life cycle of data and models.
Motivation
In spite of the availability of frameworks such as MLflow and Kubeflow, managing experiments from their conception within benchmarks to their ultimate serving as services, there is still work to be done to standardize the data preparation and feature extraction processes, generally project-specific workflows.
The typical example is a ML project where models are based on domain-specific knowledge, i.e. features.
In the worst case you have a bunch of data scientists doing their data exploration on Jupyter notebooks, trying out new features and models and maybe logging their performance to a tracking service such as MLFlow. You then have a bunch of engineers having to redesign the code to make it usable in enterprise services, perhaps written in multiple other languages other than Python and certainly not R. In addition to that, the computation of features may depend on parameters, for instance the window size for those computed on a stream. This has the effect of having multiple possible implementations for a feature, in multiple languages. In the best case, the team is versioning data used for their experiments, or keeping track of a reference to those computed over a stream, so computations are totally reproducible. A possibility for the team is then to set up a workflow to spawn processing jobs (e.g. Spark, Dask) to produce features at need before training stages. Similarly, the service serving predictions has to somehow recompute features from raw data for every request. This approach suffers the issue of having to keep consistency across multiple places: i) notebooks and exploration environments, ii) training pipelines, iii) prediction services. Even worse, imagine a continuous process where DS develop new features and those three places need to be consistently updated. But even worse, imagine having multiple projects where similar features are computed and the team has to replicate the code (if the team is smart they somehow packed it in an importable and versionable library), with the effect of having to keep versions of similar code consistent across different projects.
To fill this gap, the concept of feature stores for ML features arose in recent times. The main goal of feature stores is to decouple the computation of features from their actual use within a project, be it a training or predict stage, or just an exploratory notebook. See this medium post for an architectural overview. A very good overview of the topic is presented on featurestore.org. As presented, there already exists many offering such a service:
- SageMaker feature store
- Uber Michelangelo
- Pinterest Galaxy
- Netflix Runway
- Feast
Ok cool! So feature stores can be used to separate features and their computation from their actual use in projects and end use cases. But we have another keyword in the title: data catalogue. What's then a data catalogue? Well, it turns out that features are data assets as any other data source, and with so many versions and sources they are computed on, a way of indexing and exploring features along with actual data sources is necessary.
Specifically, data catalogues allow for an improved governance of data assets, be them actual data sources, processed data, features and models, ultimately leading to a more democratic access (i.e., with no or less intermediation) to those resources.

I found this medium post very thorough in introducing this topic.
For data catalogues there exists much available already:
- Facebook Nemo
- Linkedin DataHub - See this medium article for a comparison with other frameworks.
- Lyft Amundsen
- Netflix Metacat
The typical architecture of catalogues is that of a search engine, with multiple scrapers attempting to discover new data assets over specific domains. Projects such as Apache Atlas go in this direction, trying to scrape for data sources, such as Hive, HBase and Kafka.
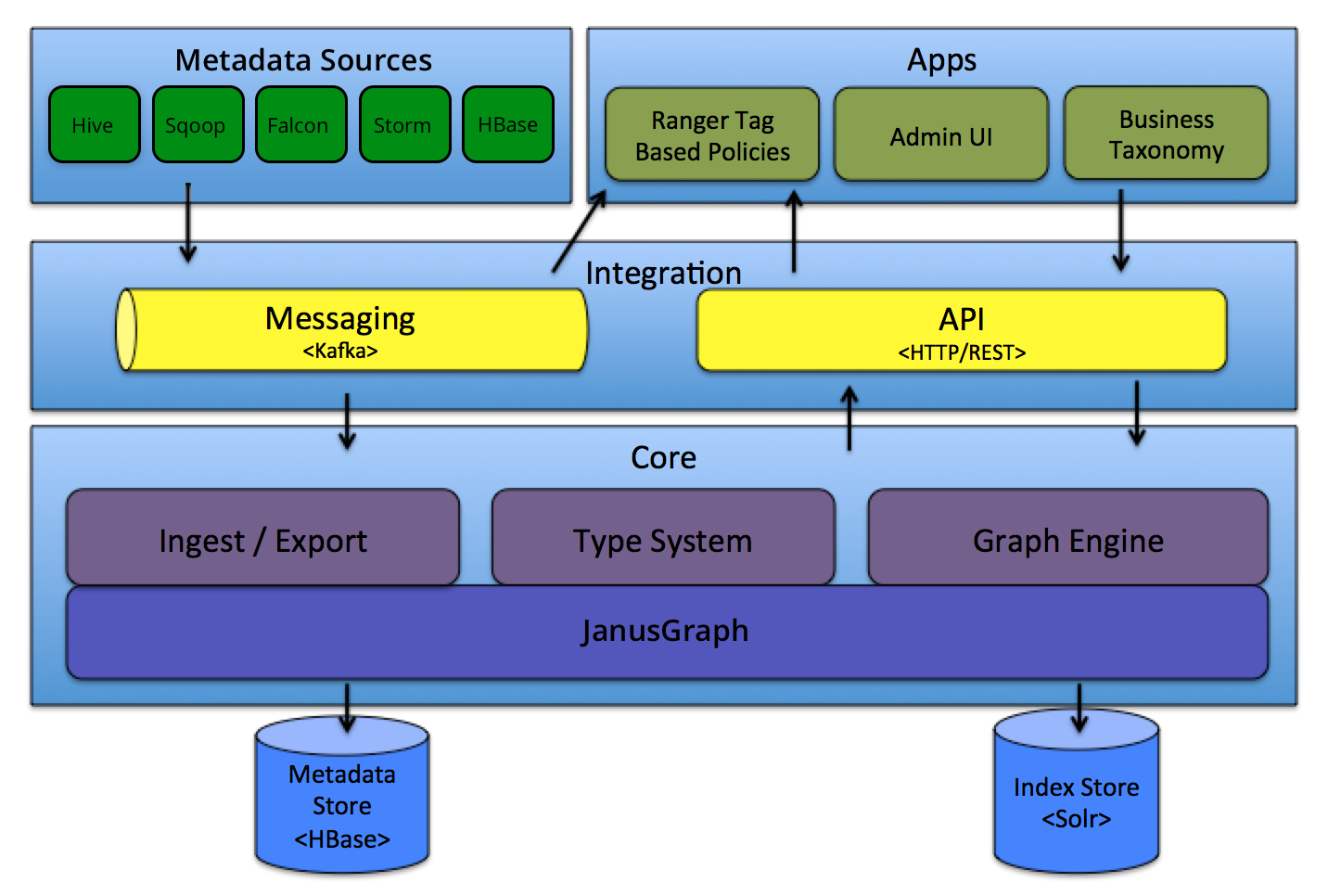
source: https://atlas.apache.org/#/Architecture
Mastro
Having the motivation above in mind, yet aiming at something super minimal, cloud-native and easy to setup and maintain, I decided during the last christmas time to implement 👷Mastro, a feature store and data catalogue written in go(lang).
Mastro comes with the following components:
- Connectors - defining a standard interface to access volumes and data bases
- FeatureStore - service to manage features;
- Catalogue - service to manage data assets (i.e., static data definitions and their relationships);
- Crawler - any agent able to list and walk a file system, filter and parse asset definitions (i.e. manifest files) and push them to the catalogue;
In addition, Mastro has a very basic UI allowing for searching catalogue assets by name or tags, available here.
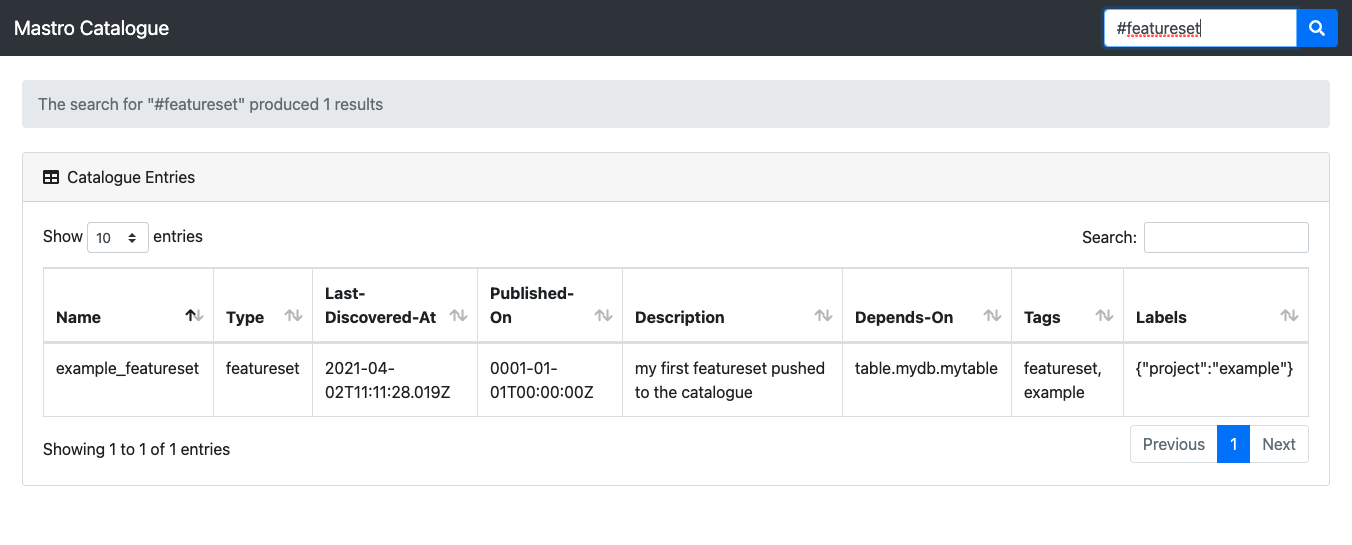
Looking forward to getting your pull requests.
No comments:
Post a Comment